
עושים סדר ב Power BI – הקשר שורה מול הקשר סינון
| תקציר המאמר: ההבדל בין Row Context ל-Filter Context ב-DAX טמון באופן הטיפול בנתונים: Row Context (הקשר שורה) פועל ברמת השורה הבודדת ומשמש בעמודות מחושבות ובפונקציות איטרציה כדוגמת SUMX. Filter Context (הקשר סינון) מתייחס לכלל הנתונים הפעילים תחת מסננים חיצוניים כמו סלייסרים (כלי פריסה). |
אם עברתם מאקסל ל-Power BI, בטח הרגשתם בהתחלה שהנוסחאות עובדות אחרת.
לפעמים הן מחשבות בדיוק מה שרציתם, ולפעמים מתקבלת תוצאה שנראית לא הגיונית.
הסיבה לכך טמונה בשני מושגים שחייבים להכיר:
הקשר שורה (Row Context) ו-הקשר סינון (Filter Context).
אלו שני הכוחות שמניעים את המודל שלכם, וכל אחד מהם עובד בצורה שונה לחלוטין.
במאמר הזה נפרק אותם לגורמים, נבין מי עושה מה, ונלמד מהי הדרך היעילה ביותר לעבוד איתם.
הקשר שורה (Row Context) – המגרש הביתי של אנשי האקסל
נתחיל מהחלק הקל. הקשר שורה הוא המקום שבו אנחנו מרגישים בבית, כי הוא עובד בצורה דומה מאוד לאקסל הקלאסי.
כשיש לנו טבלה, ואנחנו רוצים לבצע חישוב בין שתי עמודות באותה השורה (למשל: כמות כפול מחיר), המערכת צריכה לדעת להתייחס לנתונים הספציפיים של אותה שורה.
ב-Power BI, אנחנו פוגשים את הקשר השורה באופן המובהק ביותר כשאנחנו יוצרים עמודה מחושבת (Calculated Column).
ברגע שיצרנו עמודה כזו, המנוע עובר שורה-שורה, מלמעלה למטה. בכל שורה שהוא נעצר בה, הוא רואה רק את הנתונים שקיימים באותה שורה ספציפית, ומבצע את החישוב.
בואו נראה דוגמה:
לצורך הפשטות, נניח שיש לנו טבלת מכירות שטוחה (ללא קשרי גומלין) שמכילה עמודת 'כמות' ועמודת 'מחיר ליחידה'.
אנחנו רוצים לחשב את סך המכירה לשורה. נוסיף עמודה עם הנוסחה הזו:
Total Sale = Sales[Qty] * Sales[Price]
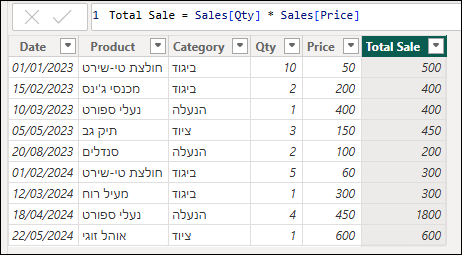
המערכת יודעת שהיא נמצאת בשורה 1, ולכן לוקחת את הכמות משורה 1 ואת המחיר משורה 1.
זהו הקשר שורה – היכולת להתייחס לשורה הנוכחית.
הקשר סינון (Filter Context) – הכוח האמיתי של Power BI
אם הקשר שורה הוא העבודה הטורית והמסודרת בתוך הטבלה,
הקשר סינון הוא מה שקורה כשאנחנו מתחילים לעבוד עם הנתונים בדוח בתוך הויז'ואלס (הגרפים והמטריצות) והסלייסרים (כלי הפריסה) שעל המסך.
זהו אוסף של מסננים שחלים על הנתונים שלנו ברגע נתון, לפני שהחישוב בכלל מתחיל.
כאשר אנחנו גוררים מדד (Measure) לתוך ויז'ואל, הוא שואל את עצמו: "אילו נתונים אני צריך לסכם עכשיו?" – התשובה לשאלה תלויה בהקשר הסינון.
המסננים מגיעים משני מקומות עיקריים:
- כלי פריסה (Slicers): לדוגמה – בחירה של שנה, חודש, סוכן או אזור.
- הוויז'ואל עצמו: אם גררנו נתונים לגרף עמודות או למטריצה על פי קטגוריה, כל עמודה או שורה בגרף יוצרת הקשר סינון לקטגוריה שלה.
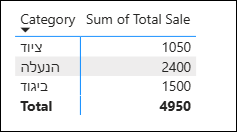
בואו נראה דוגמה:
נניח שיש לנו מדד (Measure) פשוט שמסכם את כל המכירות:
Total Sales = SUM(Sales[Total Sale])
אם נגרור את המדד הזה למטריצה שמחולקת על פי הקטגוריה, כל תא במטריצה יציג מספר שונה, מכיוון שבכל שורה במטריצה מופעל הקשר סינון אחר (קטגוריה שונה),
שמסנן את טבלת המכירות המקורית ומשאיר רק את השורות הרלוונטיות לחישוב, בדיוק כפי שנעשה בפיבוט (טבלת ציר) באקסל.
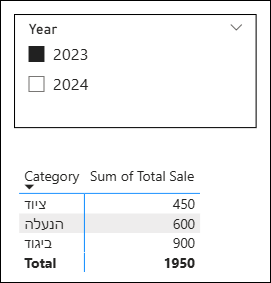
עכשיו, אם נוסיף גם סלייסר של שנה ונבחר בשנת 2023, כל המספרים במטריצה ישתנו מיד וזאת מהסיבה שכעת פועלים שני הקשרי סינון במקביל:
גם הקטגוריה (מהמטריצה) וגם השנה (מהסלייסר).
נקודה חשובה: מדדים (Measures) עובדים רק עם הקשר סינון (Filter Context).
הם לא רואים שורות בודדות, אלא מקבלים קבוצת נתונים מסוננת, ומבצעים עליה אגרגציה (לדוגמה – SUM).
כדי לגשת לשורות בודדות בתוך מדד, נשתמש בפונקציות אגרגציה כמו SUMX.
אז מתי נשתמש במה?
בדוגמה הראשונה הראיתי איך יוצרים עמודה מחושבת ב-DAX כדי להכפיל כמות במחיר. זו אמנם דרך מצוינת להדגים הקשר שורה, אבל בפועל – זו לא הדרך המומלצת לעבוד.
כלל אצבע: חישובים עושים ב-Power Query
אם אתם צריכים ליצור עמודה חדשה שמבוססת על לוגיקה של שורה-מול-שורה (כמו כמות * מחיר, או חילוץ שנה מתאריך), המקום הנכון לעשות זאת הוא ב-Power Query.
למה?
- ביצועים: המנוע של Power BI דוחס נתונים שמגיעים מ-Power Query בצורה יעילה יותר מאשר עמודות מחושבות ב-DAX. עמודות DAX תופסות יותר זיכרון (RAM) ועלולות להאט את המודל.
- סדר וניקיון: את הניקיון והכנת הנתונים עדיף להשאיר בשלב ה-ETL (כלומר ב-Power Query), ואת ה-DAX לשמור למדדים (Measures) ולחישובים דינמיים שתלויים בהקשר סינון.
ומה לגבי נתונים מטבלה אחרת (RELATED)?
הרבה משתמשים נוטים לבצע מיזוג (Merge) ב-Power Query כדי להביא, למשל, את מחיר המוצר לתוך טבלת המכירות לצורך ביצוע חישוב.
כאן דווקא ה-DAX מציע פתרון יעיל יותר שחוסך זיכרון: עבודה נכונה עם מודל נתונים (Star Schema) ושימוש בפונקציה RELATED בתוך מדד (Measure).
במקום לנפח את טבלת המכירות עם עמודות מיותרות של מחירים ושמות מוצרים,
אנחנו משאירים את הטבלאות נפרדות ומקושרות. כשאנחנו צריכים לחשב מכירות, נכתוב מדד כזה:
Total Sales = SUMX(Sales, Sales[Quantity] * RELATED('Products'[Price]))
בשיטה זו, הנתון של המחיר נשלף "על הדרך" רק ברגע החישוב, מבלי לשמור עמודה פיזית מיותרת במודל.
הערה חשובה – הדוגמה הזו היא הדוגמה הפשוטה ביותר שבה המחיר קבוע, ולא משתנה.
במקרים מורכבים יותר (כמו מחירים שמשתנים לפי תקופה), נדרשת גישה מתקדמת יותר, עליה נדבר במאמרים הבאים.
לסיכום
- הקשר שורה (Row Context): עובד "מבפנים" על השורה הבודדת. נשתמש בו ב-Power Query להכנת נתונים, או בפונקציות איטרציה (כמו SUMX) במדדים.
- הקשר סינון (Filter Context): עובד "מבחוץ". מגיע מהדוח (סלייסרים, גרפים) וקובע אילו נתונים ייכנסו לחישוב המדד.
הבנה של ההפרדה הזו היא הצעד הראשון בשליטה ב-DAX. במאמר הבא נראה מה קורה כשאנחנו מנסים לערבב ביניהם, ואיך פונקציית הקסם CALCULATE נכנסת לתמונה.
שאלות ותשובות בנושא Row Context vs Filter Context
שאלה:
מהו ההבדל המהותי בין Row Context ל-Filter Cotext?
תשובה:
Row Context (הקשר שורה) מתייחס תמיד לשורה הבודדת הנוכחית ומאפשר למשוך ערך ספציפי מאותה שורה,
בעוד ש-Filter Context (הקשר סינון) מתייחס לסט של נתונים שסוננו על ידי גורמים חיצוניים כמו סלייסרים, ציר הזמן או בחירות בויז'ואלים אחרים בדוח.
שאלה:
מתי נוצר Row Context באופן אוטומטי?
תשובה:
הקשר שורה נוצר באופן אוטומטי כאשר מוסיפים "עמודה מחושבת" (Calculated Column) לטבלה,
או כאשר משתמשים בפונקציות איטרציה (Iterators) המסתיימות ב-X כמו `SUMX` או בפונקציית `FILTER`, הסורקות את הטבלה שורה אחר שורה.
שאלה:
כיצד ניתן להפוך הקשר שורה להקשר סינון (Context Transition)?
תשובה:
הדרך היחידה להמיר Row Context ל-Filter Context היא באמצעות שימוש בפונקציית `CALCULATE`.
פעולה זו קריטית כאשר רוצים לבצע אגרגציה (כמו סכום או ממוצע) שתתחשב בשורה הנוכחית כמסנן עבור טבלה שלמה או מודל הנתונים.